
Good morning, and happy Memorial Day to U.S. readers. Today's brief is the kind of news day where a moral question, a security operations question, and an evaluation-methodology question all surface in the same 24 hours and turn out to be the same question. The headline today is Pope Leo XIV's first encyclical, Magnifica Humanitas, which made AI its principal subject and the human person its principal concern. The security operations story is Wired on the bug-hunting arms race and TechCrunch's interview with Google Cloud COO Francis de Souza. And the methodology stories are VulnLLM-R and Boiling the Frog, two benchmarks that move us past the marketing claims. If you'd rather read this once a week, subscribe to the weekly brief.
- Pope Leo XIV's first encyclical, Magnifica Humanitas, makes AI the centerpiece
- Wired: the AI era is creating a bug-hunting arms race
- TechCrunch interviews Google Cloud's COO on the real-time AI security moment
- VulnLLM-R: a sober new benchmark on frontier LLMs for cybersecurity work
- "Boiling the Frog": a multi-turn benchmark for agentic safety
1. Pope Leo XIV's first encyclical, Magnifica Humanitas, makes AI the centerpiece

The Verge reports that Pope Leo XIV released his first papal encyclical today, titled Magnifica Humanitas — Latin for "magnificent humanity" — and framed it as "safeguarding the human person in the time of artificial intelligence." The document explicitly addresses three concerns: AI-powered warfare, AI's effects on labor, and the broader question of what it means to remain "profoundly human" while the technology around us is not. This is the first papal encyclical to make AI its principal subject, and it lands at a moment when frontier labs, governments, and standards bodies are all writing their own AI doctrines in parallel.
The encyclical's significance is less about any single policy prescription and more about the audience it reaches. An encyclical is the highest form of papal teaching short of an ex cathedra definition, and Magnifica Humanitas will be read, taught, and quoted inside Catholic universities, hospital systems, K-12 networks, and labor-organizing communities for years. For technology operators, that means the conversation about AI deployment in healthcare, education, and labor is going to include a moral vocabulary it didn't have to engage with this directly six months ago. The Verge's framing pulls out the labor and warfare threads as the headline beats, and notes the encyclical's language about preserving human dignity in workflows where AI is increasingly making the decisions.
Why it matters. If you operate AI in a regulated industry — healthcare, education, finance — expect Magnifica Humanitas to surface in next year's procurement conversations and faith-based-employer policy discussions; build a one-page response that maps your governance controls to the document's concerns. If you write AI policy, the encyclical is now part of the canon you'll have to engage with in any global forum. And if you're a builder, the labor and warfare threads are the two places where the document's vocabulary is most concrete; the rest is principles. For a parallel on how the secular research community frames these same concerns, see our best AI agents 2026 roundup, which covers the deployment patterns the encyclical is reacting to.
2. Wired: the AI era is creating a bug-hunting arms race
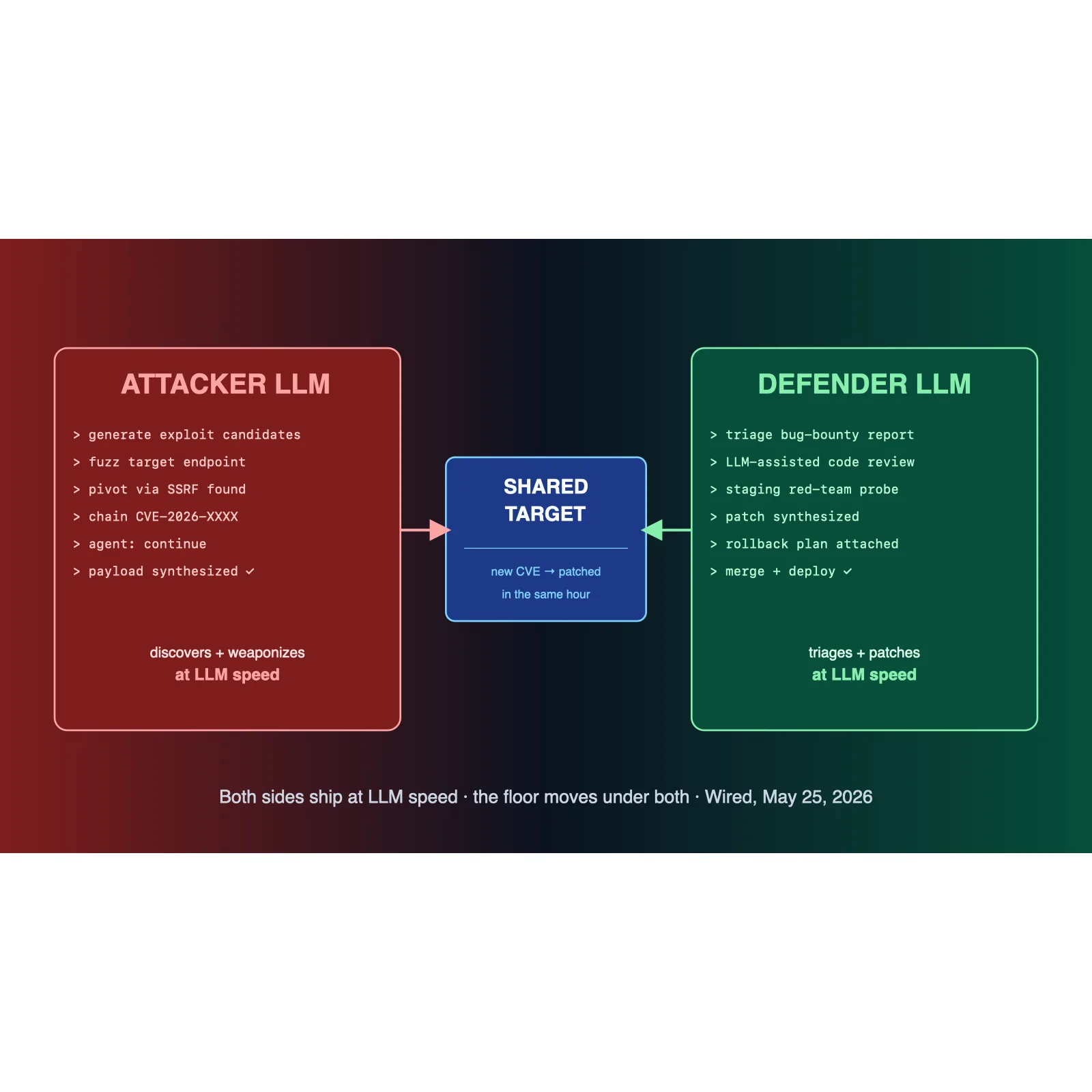
Wired published a feature arguing that AI has materially accelerated both sides of the software-vulnerability workflow at the same time, and the result is an arms race playing out at LLM speed. The attacker side gets new exploit-development tooling — fuzzers that take natural-language hypotheses, code synthesis for proof-of-concept payloads, agentic recon over public infrastructure. The defender side gets the mirror image — automated triage of bug-bounty reports, LLM-assisted code review at PR time, internal red-team agents that probe staging continuously. The piece's frame is that neither side gets a sustained advantage; the floor moves under both simultaneously, and what gets harder is the unglamorous middle — patch deployment, rollback discipline, and the political work of getting product teams to ship the fix.
The substantive read from the piece is that the rate-limiting step in 2026 security is increasingly organizational, not technical. The attacker tooling and the defender tooling are converging on similar agentic patterns. The decisive variable is whether your security org can move at the speed those agents now operate at: triage in hours rather than days, patch in days rather than weeks, and treat the AI-assisted bug report as a first-class input rather than a noisy one. Companies whose vulnerability-management programs were already mature get the lift; companies who were already behind fall further behind.
Why it matters. If you run a security program, this is the year to invest in cycle-time, not just tooling — the LLM advantage compounds on whichever side ships fixes faster. If you're a product engineering leader, the implicit ask is that security review is no longer a gate at the end of a release; it's a continuous signal during the release. And if you're operating personal infrastructure that holds value — credentials, browsing sessions, password vaults — the surface around the model matters as much as the model itself; our sister site Smart Secure Haven has the independent comparison of the major VPNs for the network-layer piece of that hardening.
3. TechCrunch interviews Google Cloud's COO on the real-time AI security moment

TechCrunch's Connie Loizos sat down with Francis de Souza, COO of Google Cloud, for a backstage interview at an event in Los Angeles. His core message: security can't be bolted on to an AI rollout, and "there's no such thing as an AI strategy without a data strategy and a security strategy. They need to go hand in hand." He flagged "shadow AI" — employees reaching for consumer tools without organizational oversight — and argued companies need to demand security, governance, and auditability from their platforms from day one. Loizos observes that even though de Souza wasn't speaking about Google specifically, it's clear from his remarks that Google itself is still working out the answers in production rather than from a finished playbook.
The substantive numbers in the piece are the part to keep. De Souza told TechCrunch that the average time between an initial breach and handoff to the next stage of an attack has dropped from eight hours to 22 seconds — a step change that makes any human-paced incident-response playbook obsolete on its own. He frames the answer as meeting machine speed with machine speed: an emerging "AI-native, fully agentic defense" in which agents run the defensive workload and humans oversee them rather than driving each step. He also flagged the underrated risk of agents wandering across forgotten internal data — "old SharePoint servers [and access controls] they haven't really updated" that suddenly become accessible because agents will find them. And LinkedIn's chief information security officer, quoted in the same piece, summarized the staffing reality with one phrase: "We're going to need people to deal with the bug-pocalypse."
Why it matters. If you're buying an AI product for an enterprise, replace the static security-posture checkbox with operational-response questions: mean time to detect, triage, and mitigate a new attack class against your AI surfaces. If you're a CISO at any scale, the 8-hours-to-22-seconds compression is the number to bring to your board — it's the cleanest argument for a budget shift toward agentic defense and away from quarterly patch windows. And if you're a Google Cloud watcher, the interview is the most direct public statement from a senior Google Cloud executive on AI-era security posture; the implicit message — that even Google operates with incomplete information about a moving threat surface — is the part that rhymes with the bug-hunting arms race above. For the broader stack of tools you'd evaluate inside that governance frame, see our best AI agents 2026 writeup.
4. VulnLLM-R: a sober new benchmark on frontier LLMs for cybersecurity work
A new arXiv preprint, "Are Frontier LLMs Ready for Cybersecurity?", introduces a dual-mode benchmark designed to answer that question with something more rigorous than vendor demos. The white-box half (VulnLLM-R) evaluates function-level vulnerability detection across C, Java, and Python. The black-box half tests web-application security against five production-style applications containing 118 ground-truth vulnerabilities spanning more than 20 CWE families — both of which the authors say they will open-source. The model panel covers GPT-5.4, Codex 5.3, Claude Opus 4.6, Sonnet 4.6, Gemini 3.1 Pro, and Gemini 3 Flash, plus two domain-specialized models, evaluated across four testing paradigms. The authors describe their findings as "sober."
The contribution worth pulling out is the dual-mode design. Most prior cybersecurity benchmarks for LLMs lean white-box (give the model the source, ask it to find the bug) or black-box (point it at a target, see if it can pivot in), but rarely both in the same study. The dual setup matters because real security work is a mix — defenders work white-box on their own code, attackers work black-box on someone else's, and a serious benchmark needs to capture both halves. The "sober" framing in the abstract is the part to read carefully when the paper is widely circulated: it suggests the authors found the gap between vendor capability claims and benchmark performance to be larger than the press cycle has been pricing in. We'll be reading the full preprint and pulling out the per-model numbers in a follow-up.
Why it matters. If you're a security leader evaluating LLM-assisted vulnerability tooling, this is the methodology to point to when asking vendors how they perform on a published, dual-mode benchmark rather than internal evals. If you're a model vendor, the dual-mode design sets a higher bar for the cybersecurity capability claims that have been a soft target since 2024. And if you're a researcher, the open-sourced web-application targets with ground-truth CWEs are the kind of artifact that compounds — they'll show up in follow-on papers all summer. For the cross-section of how these benchmarks shape the coding-assistant market, see our OpenAI Codex vs Anthropic Claude Code 2026 comparison.
5. "Boiling the Frog": a multi-turn benchmark for agentic safety
A second arXiv preprint, "Boiling the Frog: A Multi-Turn Benchmark for Agentic Safety," argues that the safety evaluations the field has relied on are calibrated to the wrong thing. Traditional safety benchmarks measure what a language model outputs in text — does it produce toxic content, reproduce bias, follow harmful instructions in a single response. When the same models are deployed as agents — taking actions in environments, calling tools, executing multi-step plans — the safety-relevant object shifts from what the system says to what it does, and the evaluation has to follow. The paper sits inside an emerging class of agentic-safety benchmarks that the authors place in their related-work survey.
The "boiling the frog" framing in the title is the substantive contribution. The paper argues that multi-turn agentic conversations create a class of failure where no single turn looks risky, but the accumulated trajectory crosses a line the model wouldn't cross in one shot. That's a known failure mode in social engineering against humans, and it turns out to be a failure mode against agents too. A benchmark that scores multi-turn trajectories rather than single responses is the only way to surface it. For practitioners deploying agents, the takeaway is that single-turn red-teaming — which has been the dominant evaluation pattern for two years — is insufficient on its own. The benchmark gives the field a shared yardstick for the multi-turn case.
Why it matters. If you're deploying agents that take real actions — email, calendar, payment, code commits — the assumption that your single-turn safety evaluation generalizes is now empirically suspect. Add multi-turn trajectory testing to the evaluation pipeline. If you're a model vendor shipping agentic capabilities, expect customers to start asking for trajectory-level eval numbers, not single-prompt refusal rates. And if you're a researcher, the paper is a useful map of where the agentic-safety literature has been heading and where the open problems sit. Pair with the VulnLLM-R writeup above — the two papers together describe a maturing evaluation stack that will determine which agentic deployments get green-lit in 2026.
What to take from today
Three threads, one story. First, the moral frame is now part of the operating environment for AI deployment — Pope Leo's Magnifica Humanitas doesn't change a single line of code but it will change the procurement conversation at every Catholic-aligned institution in the country. Second, the security operations frame is honest in 2026 in a way it wasn't in 2024 — Wired's arms-race piece and TechCrunch's interview with Google Cloud COO Francis de Souza are the same admission from two angles — the time-to-handoff number (8 hours to 22 seconds) and the bug-hunting arms race rhyme: nobody has the human-speed playbook, and the cycle-time investment in agentic defense is the durable advantage. Third, the evaluation frame is finally catching up — VulnLLM-R and Boiling the Frog are the kind of benchmarks that let buyers, regulators, and the press ask better questions than "is it safe." The keynote stage gets the press; the benchmark paper gets the procurement decision.
Tomorrow's brief lands at 15:30 UTC. If you'd rather read this in your inbox once a week — just the five stories that actually matter — subscribe here.